
I was recently trying to scrape a Japanese static HTML website with Python 3, requests, and Beautiful Soup.
The website was a .jp-site, but the text appeared to be in English. DevTools also confirmed that the HTML markup was in English.
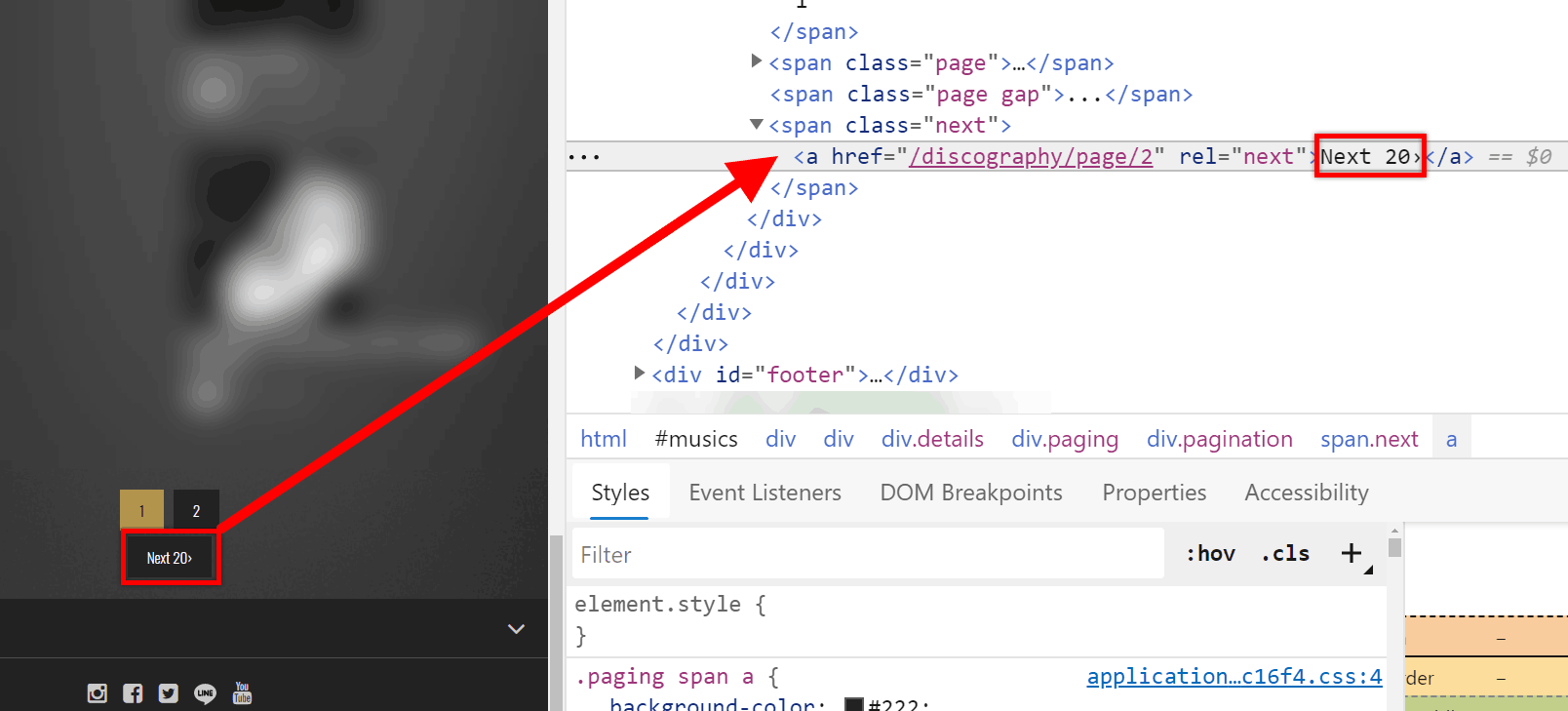
However, to my surprise, the code I was receiving when I was trying to scrape the website with requests showed something different…
Those are Japanese characters, right? So how can the HTML markup and the website text be in English when requests is getting a different language? 😲
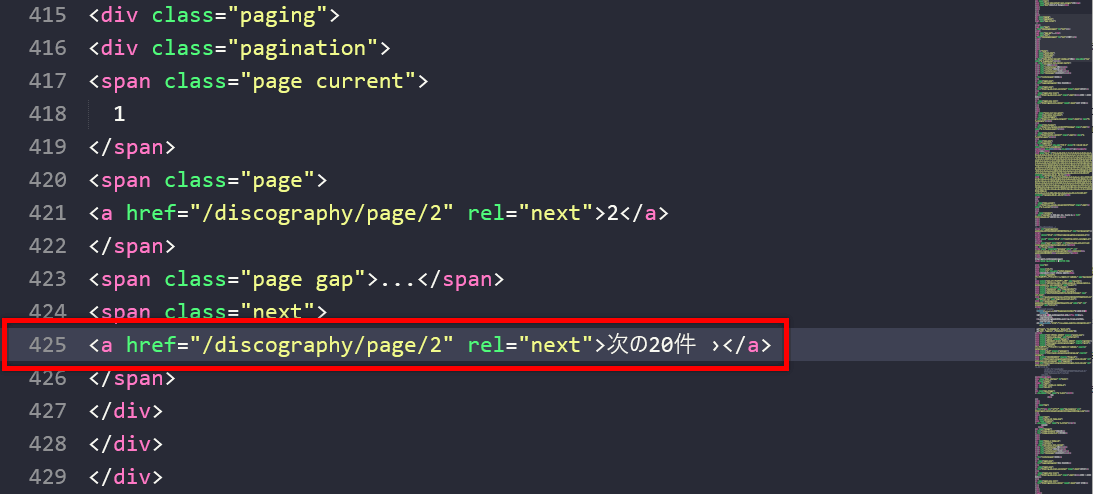
Using my “phenomenal deduction skills” 😅, I realized that this most likely has to do with the type of requests my web browser sends to the website compared to what kind of request my script is sending.
I used DevTools to copy the request my web browser was sending. I could see that the browser specifically sent a request header called “Accept-Language“.
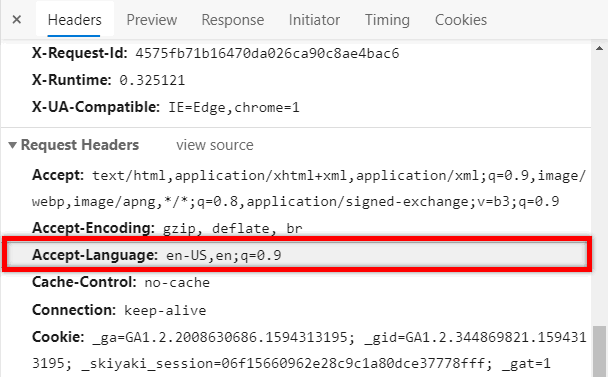
I generally know little about HTTP, but I managed to find an explanation from MDN Web Docs:
The Accept-Language request HTTP header advertises which languages the client is able to understand, and which locale variant is preferred. “…” This header is a hint to be used when the server has no way of determining the language via another way, like a specific URL, that is controlled by an explicit user decision. It is recommended that the server never overrides an explicit decision.
MDN Web Docs, July 2020
So, in other words, my web browser was sending this “Accept-Language” request on my behalf, in hopes to receive the webpage in English.
So now the question was how could I do the same in my Python script… 🤔
The Python requests library’s official documentation says we can add custom headers to send specific request header values to the server. Like this, for example:
import requests
from bs4 import BeautifulSoup
url = 'https://yourpage.com/'
headers = {"Accept-Language": "en-US,en;q=0.9"}
print(requests.get(url, headers=headers).text)This will make Python ask for the page in English.
Finally, this gave me the HTML result I wanted!
As you can see from the screenshot, the letters are in English.
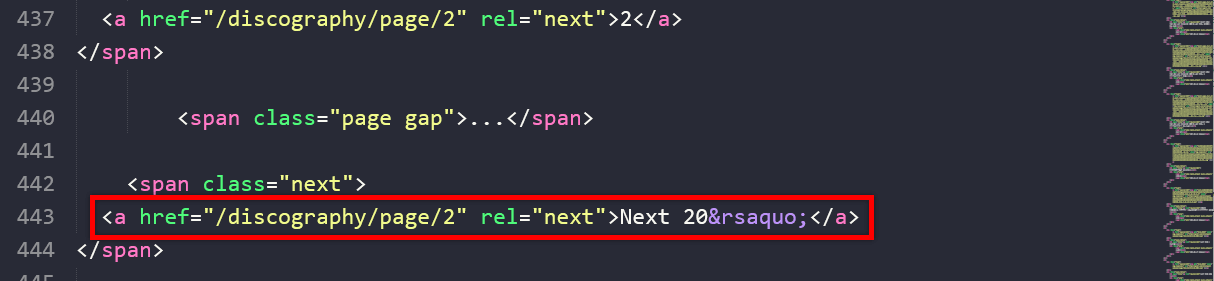
Voilà!